A recipe for online merchants

Duration: 10 min | Date: Mar 13, 2024
E-commerce is a wild world where merchants want to grow their business by selling their products online, but have to deal with malicious actors who seek buying them for "free" and reselling these products to real customers with a big discount. This is a win-win transaction for them, but a big loss for the merchant. In fact, most Payment Service Providers state that it is the responsibility of the e-commerce merchant to detect and block Fraud, and they may be charged if they do not do so. That's where Machine Learning comes into play.
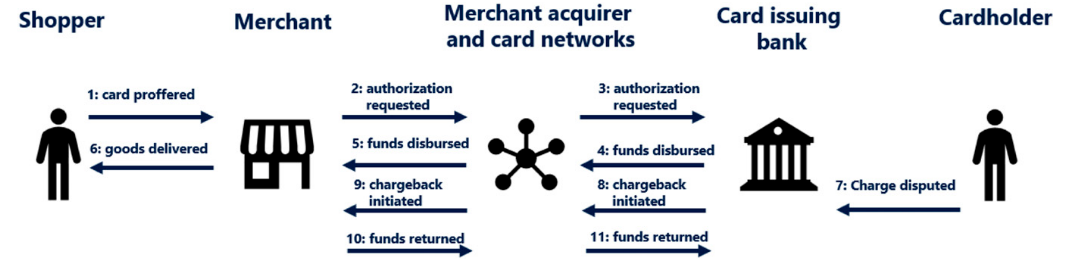
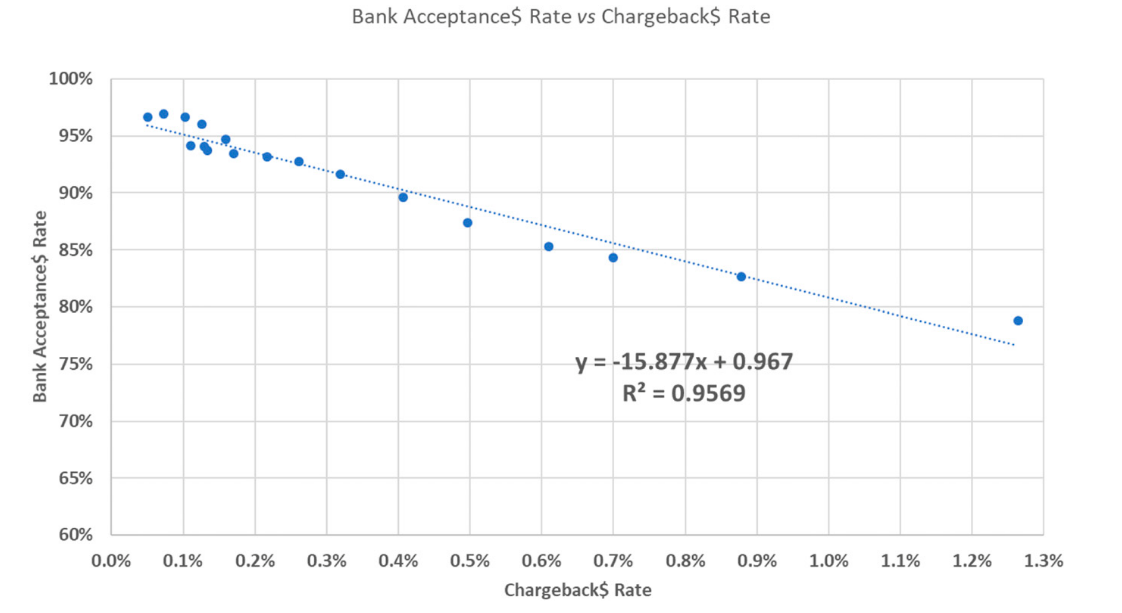
First of all, it is worth diving in the definition of a Fraud. Let's assume a transaction made by a shopper on a website. The merchant receives funds, the goods are delivered to the customer and life goes on. For most transactions, that's it. However in rare cases, several weeks or months later, a random cardholder may be surprised by an unknown charge on his bank account that he never intentionaly did and dispute it to his bank. In that case, the bank will initiate a chargeback, that will be sent to the merchant through the card network. If the merchant can not show that the chargeback is an abuse from the cardholder, he has to return the funds to the cardholder, with additional chargeback fees charged by the Payment Service Provider (a few dozens euros by transaction). On top of that, if an e-merchant is victim of too many frauds, the banks will accept less payments for this company, as illustrated by Microsoft in the figure below.
You can imagine how this money can then be used, from isolated fraudsters trying to make easy money to organized groups willing to finance criminal organisations. This is an ethical issue that businesses are willing to tackle. But the most important problem for these companies is the exponential growth of the number of frauds when a breach is open. That is what fraudsters are looking for : easy money with easy breaches. And as in every security domain, the best defense for companies is too create as much friction as possible on the fraudster path, to deter the malicious actor from attacking their business and make them attack other more vulnerable merchants.
The friction concept is interesting for Machine Learning Engineers. It means that we do not have to develop a perfect model
catching every single fraud. Be sure that if an attacker is motivated enough, he will manage to pass through your model or infrastructure.
For business stakeholders, this is sometimes hard to accept, as fraud raises strong feelings. Nobody wants to be victim of fraud.
However, it is key to look at the cost of frauds and put the fear emotions in perspective.
Indeed, it may turn out that in some segments of your e-commerce business, fraud chargebacks are not that expensive, depending on your Payment Service Provider agreement.
In this case, you should be much more laxist : if you try to block more frauds, you will necesarily block more legit customers.
Merchants can take advantage of their transactional data, thanks to Machine Learning. For Fraud Detection, Feature Engineering is key. Thus, ML teams must spend time with Fraud experts to determine the characteristics of each fraud attack that the merchant has undergone in its history. Here are some risk factors that can be translated in features:
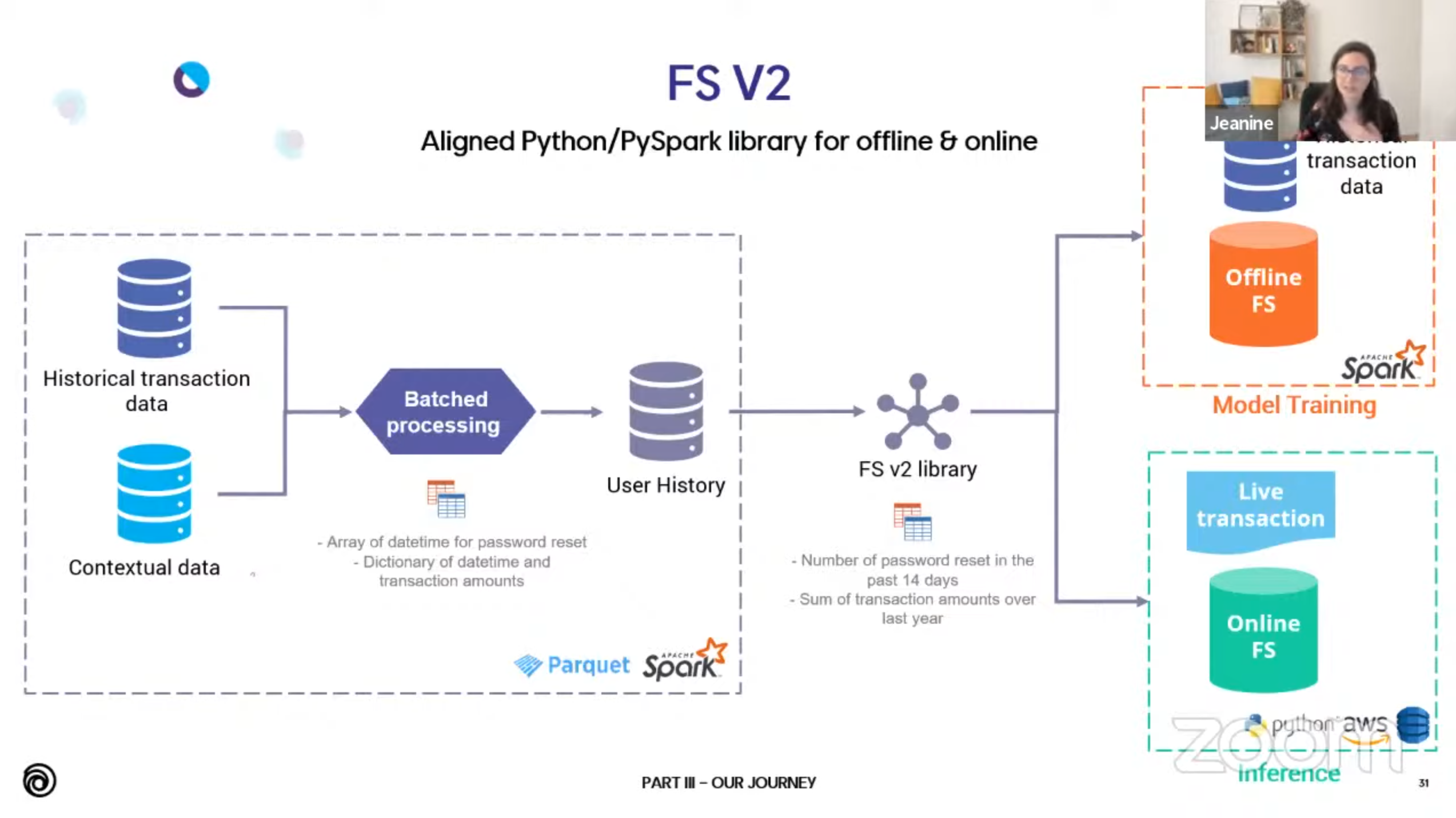
Futhermore, The Feature Store is a more reliable way of computing features for this kind of application: the definitions are centralized, they are tested and the values are monitored. It ensures an alignment between offline (training) and online (real-time inference) feature values. Below is a simple schema describing a type of Feature Store. If you want more detail, you can have a look at this great talk by Jeanine Harb, Data Engineer.
On tabular data, the secret sauce remains having strong features correlated with fraud patterns and train Gradient Boosted Trees. Add undersampling to rebalance your dataset before optimising a XGBoost model, and do not take the last few weeks of transactions in your training set as the data is too corrupted. Feature Engineering and collaboration with fraud experts is always the most effective strategy to refine your models, ensuring alignment with business objectives by catching fraud efficiently and accepting most of legit users.
Moreover, there are awesome explainability tools such as explainerdashboards. This is very convenient to debug a tree-based model, fully understand it and explain the model's decisions when there is a customer inquiry. On top of that, you can lastly define unit tests on key segments of your dataset to protect you against performance regression when a new model is deployed.
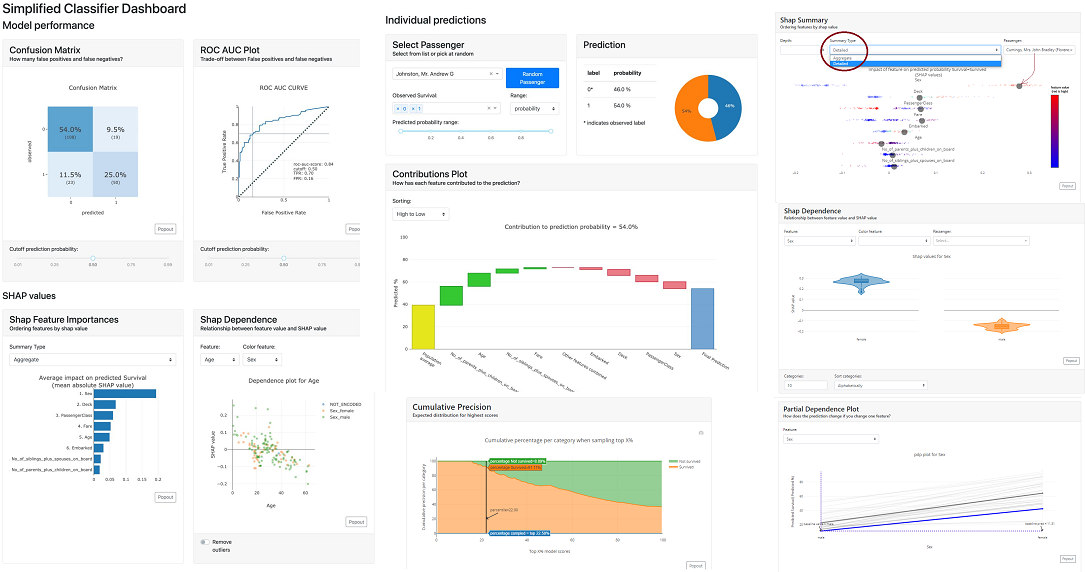
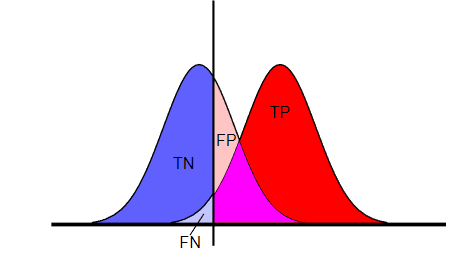
When a transaction is blocked, the payment flow ends, thus you will get no label for it.
It means that you only have the labels for transactions that your model accepted, which will be fraud or legit.
In statistical terms, these are True Negatives (Legit transactions that were accepted by the model) and False Negatives (Frauds that were accepted by the model).
To compute classification metrics, you also need some positive instances, things that were blocked by the model.
A solution to overcome this challenge is the Control Group : For a subsample of all the transactions in a day, you bypass the model decision and just log the Model score so that the payments of this subset are completed
and you can analyze your model's decisions. Of course, you have to be careful on how you select the customers / transactions you select for the Control Group in order to forbid fraudsters from taking advantage of it.
This allows you to rigorously assess the impact of your fraud detection system and refine your strategies.
The concept of Control Group is extensively presented by Stripe in a PyData talk.
In the end, the success of Fraud Detection projects is reflected in key metrics such as a gain in net sales due to less legit transactions being blocked, and the valuable time saved for fraud experts. You also decentralize knowledge so that the in-house tool can be owned by more people.
Now that your Fraud Detection model is deployed (and the platform is built), the Fraud Detection product is live and the team has to maintain it. First, It means Monitoring it using tools like Grafana for real-time monitoring and Tableau or Streamlit for dashboards. Alerts need to be set properly and thresholds fine tuned so that you can react as soon as possible when there is an incident (fraud attack, platform down...)
Then, it means having the good set of tools to retrain and deploy Machine Learning models when there is an emerging fraud pattern. For this, you need :
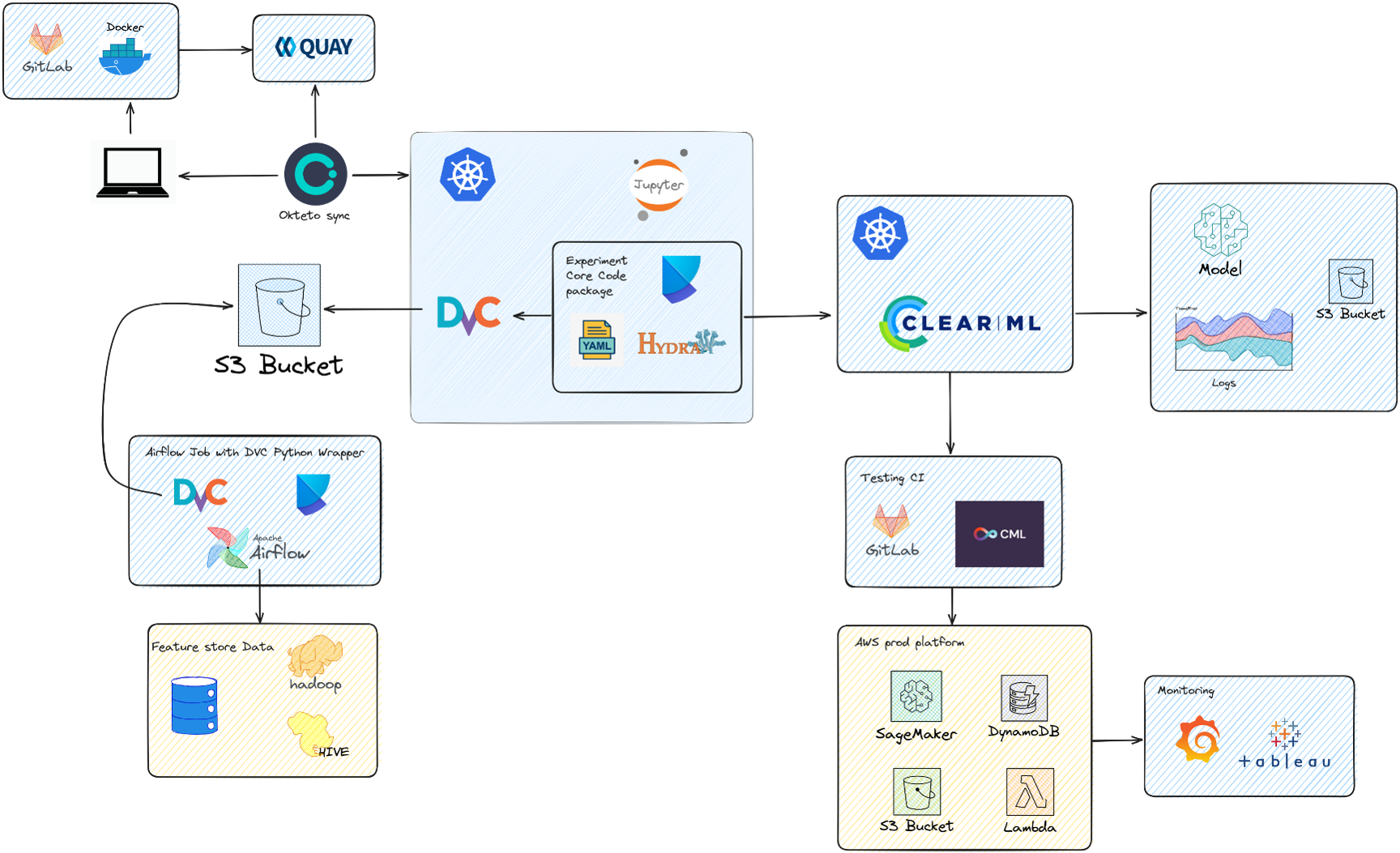
This is just another story of Machine Learning models in production showing that Modeling is only the tip
of the iceberg in production use cases. It also reminds us that Decision Trees still rock in business and it is a must have skill
to master classical ML algorithms.
On top of modeling, there is so much to discover in MLOps, DevOps, Data Engineering,
Software Engineering, making the Machine Learning Engineer role a wonderful place for curious and creative people.